


Last month, Qualcomm unveiled the Snapdragon 855 mobile platform. The Snapdragon 855 is the mobile platform that will power most Android flagship smartphones in 2019. Qualcomm has made substantial year-on-year improvements with their next generation mobile platform. The Snapdragon 855 mobile platform is built on a 7nm manufacturing process and offers an impressive 45% jump in CPU performance over the Snapdragon 845. The improvements in computation across the board allow Qualcomm to boast excellent AI performance on the new Snapdragon 855. There’s a lot of information to unpack here and we’ve done our best to show how Qualcomm has improved performance and AI on the Snapdragon 855. However, we still had questions of our own after the product unveiling, so we sat down with Travis Lanier, Senior Director of Product Management at Qualcomm, to talk about the Kryo 485 CPU and AI on Qualcomm’s new mobile platform.
Mario Serrafero: “45% [jump], it’s like the biggest ever. Let’s unwrap that. We have the A76 base, 7nm—those are big contributors. It seems that ever since you guys moved away from custom cores, some publications and audiences haven’t had much of a clue as to what the Built on ARM license entails in terms of what it can allow you to do. You’ve been pretty secretive about what that entails [too]. Now on stage for one of the first times you have, at least beyond Q&As, …but for the first time you’ve shown what some of the improvements were, and that’s cool. So we were wondering whether you would like to expand on how Qualcomm tuned the Kryo 485 to squeeze more [out] of ARM’s base, whether that’s expanding on the stuff you’ve exposed over there or something that you haven’t presented.”
Travis Lanier: “So I can’t really say too much more than other what was in my slides. Maybe at a future date we can, so we can sit down and get some experts who actually did the work; I know the high-level talking points. But as you know, A76 is already a high-level design—it’s pretty good. And it’s one of the reasons when we saw ARM’s roadmap. So I’m like, okay, maybe we should work with these guys more closely, because it looked very strong. And just going back to your comment on customization versus ARM. So okay, there’s all these things that you can do. And if you’re doing something, and it needs to have differentiation, so you can do something a hundred percent or partner with them. And [as in] previous years, we’re a little bit more about integration. So buses, and how we hooked up to the system, their security features that we put into the CPUs, cache configurations. Now that the engagements have been going longer, we were able to do a deeper customization on this one. And that’s how we were able to put some of these things in there, like larger [out-of-order] execution windows, right, so you have more instructions in flight, data pre-fetching is actually one of the areas where there’s the most innovation going on in the microprocessor industry right now. A lot of the techniques for a lot of these things are pretty similar, everybody uses a TAGE branch predictor nowadays, just how big you provision it, people know how to do out-of-order, and forwarding and all that stuff for bigger caches. But pre-fetching, there’s still a lot of, it’s one of those dark art type things. So there’s still a lot of innovation going in that space. So that’s something that we felt we could help with.
And then just because we feel that we generally do a better job with… usually we can implement a design faster than others can integrate a process node. And so when we put some of these things in there, like when you go more out-of-order, it is more stress on your design, right? It’s not free to add all these execution things in there. So, to be able to do that, and not have a hit on your fmax. Yeah, that’s part of the engagement that we have with ARM, like how do you pull them off?”
Mario Serrafero: “Just out of curiosity, in the presentation, you had talked about efficiency improvements coming from the pre-fetching, were you talking about power efficiency, performance improvements, a bit of both?”
Travis Lanier: “All the above. So, by its nature, we’re doing pre-fetching—you’ve pulled things in the cache. So when you have the cache not doing as many memory accesses, now there’s a flip side to pre-fetching: If you do too much pre-fetching, you are [using] more memory because, you know, [you’re] doing too much speculative prefetching, but as far as, if you have stuff in and you’re pulling the right stuff, then you’re not going out to memory to pull it in there. So if you have a more efficient prefetcher, you’re saving power and you’re increasing performance.”
Mario Serrafero: “Okay, cool, yeah. Yeah, I didn’t expect that you would be able to expand much more beyond that but, it’s interesting that if you say that now you guys are customizing more and maybe you’re able to share more in the future then I’ll keep an eye open for that. So the other kind of head turner, at least among people I’m surrounded by, is the prime core. So we were expecting kind of more flexible, cluster arrangements for a couple years now with [the] inclusion of DynamIQ and that we expected other companies are moving away from [the] 4+4 arrangement. So two questions: What was the motive behind the prime core? How is the prime core benefiting the user experience, because our readers would like to know why there’s just a lone core over there, and also why it’s not quite a lone core? Wouldn’t sharing the power plane with the performance cluster kind of mitigate some of the utility that you could obtain if you were using DynamIQ and kind of sitting [it] on its own?”
Travis Lanier: “So let’s talk about different clocks and different voltage planes first. So every time you add a clock and every time you add a voltage, it costs money. So there’s a limit to the number of pins you put on the package, there’s more PLLs you have to have for different clocks and there’s just increased complexity. So there is a trade off to doing things. We went kind of extreme at one point; we had four different domains on four different clocks, so we had experience with that and it was expensive. Kind of when you start to go big.LITTLE, you have the small cores on [the] small cluster and they don’t quite need that same granularity, so to speak, of a separate clock between the small cores. Yes, it’s kind of in the air what you do with those. So when you have a big.LITTLE system, then conversely you have these big cores. Well, okay, do you put each of those on a big clock? Well, you’re not running on those all [the] time, if you’re actually in a low enough situation where a clock unoccupied will run on a small core anyway. So really, it’s kind of two of them is good enough there.
And then you get to where we had this prime core where okay, well, we have a separate clock core, which can run up to a higher frequency. But these other cores, the other performance clusters, can’t go up to the same high frequency. So if you want to get that full entitlement of that core, you need to have that third clock for that one. So what does this core do? We touched on that a little bit. Big things will be [the] app launcher and web browsing. And so why only one core? Okay, things are getting more multithreaded now. For example, game engines—I’ll come back to that in a second—are moving very aggressively towards more threads. But if you look at most apps, even if they have multiple threads, I’ll use the Pareto rule, like most of them, 80% of the load is in one thread. So you may do [an] app launch, and it may fire up and light up on all 8 cores. But more than likely, 80% of it is in one dominant thread—it’s in that one core. Web browsing is still primarily, well, JavaScript, I would say—web browsing has gotten a little bit better with multithreading where you can have multiple images and you can decode them. But, for example, JavaScript—[a] single thread is going to run on one core. So there is a large number of use cases that benefit from having this one core that went really high.
Now we have three cores run a little bit at a lower frequency, but they’re also more power efficient. And so like, whenever you—I don’t know how much you know about implementation of cores—but whenever you start to hit the top of the frequency, and the implementations of these cores, there’s a trade off in power, things start to get exponential in those last few megahertz or gigahertz that you have. Yeah, and so I talked about a second ago, where, hey all games are starting to get multithreaded, like all of a sudden, if you look back, there was a couple of games not too long ago, and they’re just using one thread. But it’s weird how quickly the industry can change. Like in the past year, year and a half, they’ve literally started putting all these games into… I’ve gotten excited over these high fidelity games. And so whereas a lot of stuff just even like six months to a year ago, before, it’s actually flipped over all of China. In China, I hear “I don’t really care about big cores, give me a eight of anything, give me eight of the smallest cores so I can have eight cores.” They’ve changed because they want these games, these games require big cores. And now we’re getting feedback from partners that “no, we actually want four big cores,” because of all the advanced games that are coming out. And they’re going to use all these cores.
So when you game, you don’t game for 30 seconds, or 5 minutes, you game for longer. So, it makes sense, we have these three other cores in most of your multithreaded big core use cases, they want to have a little bit more power efficiency. It kind of balances out, you have this higher performance core when you need it for some of these things within some of these sustained cases where they also have big cores and you have this more power efficient solution to pair with that. That’s kind of the thinking—it’s kind of a little bit of an unusual symmetry. But hopefully that answers why [there’s a] prime core, why don’t you have separate clocks, and why don’t you have separate voltages? And so I think I touched on all those.”

Kryo 485 CPU core configuration. Source: Qualcomm.

Mario Serrafero: “Now, heterogeneous compute. That’s what Qualcomm has been stressing since the move away from the old branding to the mobile platform, and that kind of [a] descriptor, and also aggregating blocks from describing certain performance metrics like AI. How has that evolution been in switching to a more heterogeneous compute approach? Anywhere from design to execution to marketing, or whatever you can touch upon.”
Travis Lanier: “It goes a little bit back and forth. But in the end, you have to have these engines because the name of the game in mobile is power efficiency. Now you sometimes see it move back to a generalization every once in awhile. If you go back to your original, even for smartphones, feature phones had multimedia and camera capabilities to some extent and so they have all these little dedicated things because you couldn’t do it. If you go back to the phones that are built on the ARM 9 or an ARM 7 they all had a hardware acceleration widget for everything.
But to give you an example, where something went general and then now they’re asking for hardware again, would be JPEG. There used to be a JPEG accelerator. The CPU eventually got good enough and it was power efficient enough and the JPEGs kind of stayed the same size that, hey, you know what, we’ll just go ahead and do it on the CPU [as] it’s just easier to do it. Now, as pictures get bigger and bigger, all of a sudden, people are going, you know, actually, I want these really gigantic photo file sizes to be accelerated. The CPUs [are] kind of either not fast enough or burning too much power. It’s just suddenly that there’s interest in potentially having JPEG accelerators again. So it is not always a straight line how things go, then you have to look at what’s going on right now with Moore’s Law. Everyone keeps talking about, hey, you may not be dead, but it’s slowing down a little bit, right? So if you’re not getting that power boost, or performance boost from each next node, how do you continue to put more functionality on the phone if you don’t have that overhead? So you could just put it on the CPU. But if you don’t have more headroom for your CPU, how do you accelerate these things? Well the answer is, you put all these specialized cores and things more efficiently. And so it’s that natural tension.
You’ll see people being forced to do these things for common functions as maybe not everyone’s going to be on the bleeding edge. But we’re certainly going to try staying there as long as possible, but we can’t force the fabs to move to the next node if it’s not there necessarily. So that’s why you have to focus on continual innovation and these architectures to continue to get better performance and power efficiency. So that’s our strength and our background.”
Mario Serrafero: “Even though there’s been this move to heterogeneous compute, on Qualcomm’s part, many audiences and certainly many publications, certainly many enthusiasts, surprisingly, who you think would know better, they still think of, consider, and evaluate, the blocks as separate entities. They still focus on, “I want to see the CPU numbers because I care about that.” They want to see GPU numbers because they like games, so on and so forth. They don’t consider them as communicated parts of one integral product. How do you think that Qualcomm has, and is, and can, shatter that paradigm as competitors actually keep focusing on that specific block-by-block kind of improvements in marketing? Specifically, [we’ll] move on to the neural networks, the neural engine stuff later.”
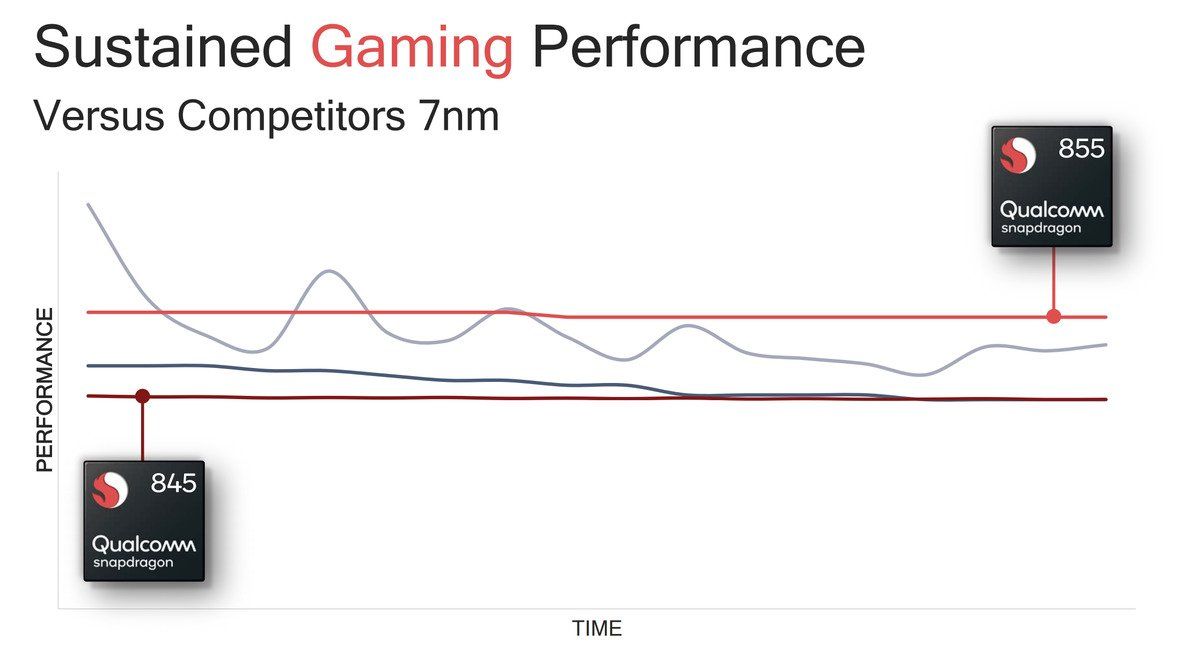
Travis Lanier: “I hope I touched on some of that today. We focus on, for example, sustained gaming, so maybe you score well on all the gaming benchmarks. People get obsessed about that. But really, what matters is, if you’re playing your game, does your frames per second stay consistently where you want it to be at the highest point for these things? I think people put way too much weight into a number for one of these blocks. It’s so hard, and I understand that desire to give me one number that tells me what the best is. It’s just so convenient, especially in AI right now, it’s just nuts. Even with CPU benchmarks, what does a CPU benchmark measure? They all measure different things. Take any of the benchmarks, like GeekBench has a bunch of sub components. Do you see anybody ever tear apart and look into which one of these sub components is most relevant to what I’m actually doing?”


Mario Serrafero: “Sometimes, we do.”
Travis Lanier: “Maybe you guys do. You guys are like an outlier. But like maybe one CPU is better on this and maybe one’s better on another. Same thing with SPEC, people will highlight the one SPEC, well, okay, there’s a lot of different workloads within that. And they’re pretty tight things, but even SPEC, which we actually use for developing CPUs, if you look at the actual workloads, are they actually relevant? It’s great for comparing workstation workloads, but am I really doing molecular modeling on my phone? No. But again, that’s my point is, most of these benchmarks are useful in some way, but you have to understand the context of what [it’s] for and how you get there. And so it’s really hard to distill things down to one number.
And I see this especially—I’m pivoting here a little bit—but I see this with AI right now, it is bonkers. I see that there’s a couple of different things that wouldn’t get one number for AI. And so as much as I was talking about CPU, and you have all these different workloads, and you’re trying to get one number. Holy moly, AI. There’s so many different neural networks, and so many different workloads. Are you running it in floating point, are you running it in int, running it in 8 or 16 bit precision? And so what’s happened is, I see people try to create these things and, well, we chose this workload, and we did it in floating point, and we’re going to weight 50% of our tests on this one network and two other tests, and we’ll weight them on this. Okay, does anybody actually even use that particular workload on that net? Any real applications? AI is fascinating because it’s moving so fast. Anything I tell you will probably be incorrect in a month or two. So that’s what’s also cool about it, because it’s changing so much.
But the biggest thing is not the hardware in AI, it’s the software. Because everyone’s using it has, like, I am using this neural net. And so basically, there’s all these multipliers on there. Have you optimized that particular neural network? And so did you optimize the one for the benchmark, or do you optimize the one so some people will say, you know what I’ve created a benchmark that measures super resolution, it’s a benchmark on a super resolution AI. Well, they use this network and they may have done it in floating point. But every partner we engage with, we’ve either managed to do it 16 bit and/or 8 bit and using a different network. So does that mean we’re not good at super resolution, because this work doesn’t match up with that? So my only point is that AI benchmark[ing] is really complicated. You think CPU and GPU is complicated? AI is just crazy.”
Mario Serrafero: “Yeah, there’s too many types of networks, too many parameterizations—different parameterization leads to different impacts, how it’s computed.”
Travis Lanier: “It’ll keep reviewers busy.”
Mario Serrafero: “But like if you want to measure the whole broad of things, well it’s a lot more difficult. But yeah, nobody’s doing it.”
Mishaal Rahman: “That’s why you guys are focusing more on the use cases.”
Travis Lanier: “I think in the end, once you show use cases, that’s how good your AI is right now. It comes down to the software, I think it will mature a little bit more in a few years. But right now there’s just so much software work that has to be done and then changes like, Okay, well, this network’s hot and then like, next year, “Oh, no, we found a new network that’s more efficient in all these things,” so then you have to go redo the software. It’s pretty crazy.”
Mario Serrafero: “Speaking of NN, you kind of did the transition for me, less awkward transition thinking for me. Moving on to the Hexagon. This is kind of one of the components that is least understood, I would say, by consumers, even most enthusiasts, certainly my colleagues. You know, especially given that it was not introduced as an AI block, and like kind of the whole digital signal processing idea, you know, when you introduce something that original idea kind of sticks so if you’re doing to do something, okay it’s a neural thing with the neural, neural, neural brain intelligence, it kind of sticks with people. They have the AI machine learning neural, neural, neural labels for other solutions. So we want to maybe give you a chance to explain the evolution of the Hexagon DSP, why you haven’t moved away from that kind of engineering-sound[ing] names like Hexagon DSP, vector extensions, and so on that are not like as marketing friendly. But yeah, just like maybe like a quick rundown of how it’s been for you at the forefront of DSP to see it go from the imaging workload beginnings to the brand new tensor accelerator.”
Travis Lanier: “It’s actually an interesting point because some of our competitors actually have something they’ll call a neural engine or a neural accelerator—it’s actually a DSP, it’s the same thing. So I guess the name is important, but you touched on an important point and in all honestly when we put this out there it was for imaging, we just happened to support 8 bit. And I remember we were presenting at Hot Chips and Pete Warden of Google kind of tracked us down and was like, “Hey, you..so you guys support 8 bit, huh?” Yeah, we do. And so from there, we immediately went out and like, hey, we’ve got all [these] projects going on. That’s when we went and ported TensorFlow to Hexagon, because it’s like, hey, we’ve got like this 8 bit supported vector processor out there to do that, and it was on our Hexagon DSP. If I had to go all over again, I would probably call it the Hexagon Neural Signal Processor. And we still have the other DSP, we do have scalar DSPs and that’s a DSP in the truest sense. And then we call this kind of a vector DSP. Maybe we should rename it, maybe we should call it a neural signal processor because we’re probably not giving ourselves as much credit as we should for this because, like I said, some people they just have vector DSPs and they’re calling it whatever, and they haven’t revealed whatever it is. Did I answer your question?”

Hexagon 690 Overview. Source: Qualcomm.

Mario Serrafero: “So, yeah, that’s right probably most of it.”
Travis Lanier: “What was the second question?”
Mario Serrafero: “Just how you saw kind of that development internally. What’s it been like: the experience, the difficulties, the challenges, whatever you want to tell us about? How [have] you seen the evolution from the image processing beginnings to the tensor accelerator?”
Travis Lanier: “It’s been a little frustrating because it’s like the thing that makes me cringe is like some of the press will raise their hand and be like, “Qualcomm, what you’re so behind! Why didn’t you—When are you going to get like a dedicated neural signal processor?” and I just want to like pound my head. I was like we were the first one to have a vector processor! But that said, we edit this and there’ll probably continue to be more things as we learn more about AI. So, we did add this other thing and yeah this one is—it only does AI, it doesn’t do image processing as part of the hexagon complex so you offer … as we still call it the Hexagon DSP, we’re calling the whole complex the Hexagon processor [to] try and get a captured name for whole hexagon thing now. We did add stuff which actually [is] more directly compute, I shouldn’t say directly compute, like it has this automatic management of how you do this higher order map of where you’re multiplying matrices.”
Mario Serrafero: “Tensors are actually pretty hard for me to wrap my head around. It’s just like they kind of wrap around themselves too, anyway.”
Travis Lanier: “Yeah, I thought like, I took my linear algebra classes in college. I did that like man, “I hope I never have to do that again!” And they came back with a vengeance. I guess I was like, ‘Oh man, differential equations and linear algebra are back with a vengeance!'”
Mario Serrafero: “I feel a lot of my colleagues haven’t caught up on this. They still think that there’s this mystifying aspect to the NPU when it’s just a bunch of matrix multiplication, dot products, nonlinearity functions, convolutions, [and] so on. And I don’t think that personally, that kind of the neural processing engine name helps, but that’s the thing, right? How much of it is either not being expanded, obfuscated, kind of the underlying math shoveled, by the naming conventions, and what can be done perhaps? I don’t know if you thought about this. [What] can be done to inform people about how this works? How it’s not just like, why for example, why the DSP can do what the other new neural processing engines can do? I mean, it’s just math, but it doesn’t seem that users, readers, some journalists, understand that. What can—I’m not saying it’s Qualcomm’s responsibility—but what do you think could be done differently? It’s probably my responsibility.”
Travis Lanier: “Honestly, I’m starting to surrender. Maybe we just have to name things “neural.” We just talked about how linear algebra and differential equations made our heads spin when we started looking at these things, and so when you start trying to explain that to people like when you start doing the regression analysis, you look at the equations and stuff, peoples’ heads explode. You can teach most people basic programming, but when you start teaching them how the backpropagation equations work, they’re gonna look at that and their heads are going to explode. So yeah, fun stuff. They don’t want to see partial derivatives…”
Mario Serrafero: “Chains of partial derivatives, not across scalars but across vectors and including nonlinear functions.”
Travis Lanier: “Good luck with that! Yeah, so it’s hard and I don’t know that most people do want to know about that. But I try: I put in a little thing like, “Hey, all we’re doing here is vector math. We have a vector processor.” And I think people look at that and are like, “Okay, but man I really want a neural accelerator.” “Tensor” is still mathematical, but I think people may associate that a bit more with AI processing.”
Mario Serrafero: “Could be like bridging the gap, the semantic gap.”
Travis Lanier: “In the end, I think it’s come down to, we probably just have to come up with a different name.”
All graphics in this article are sourced from Travis Lanier’s presentation at the Snapdragon Tech Summit. You can view the presentation slides here.



0 comments:
Post a Comment