


When Qualcomm unveiled their new Snapdragon 855 mobile platform, they touted substantial improvements in all aspects of mobile computing. For the average user, it’s easy to understand the end user benefits behind the CPU and GPU improvements that Qualcomm made in the Snapdragon 855. Better CPU performance translates to apps loading faster and better GPU performance translates to better framerates when gaming. What’s less intuitive for users to understand is AI (artificial intelligence), and specifically, machine learning techniques that app and services increasingly adopt such as artificial neural networks. Qualcomm made huge gains in AI workload performance with the Snapdragon 855 thanks to improvements in computing across the board, and especially due to the revamped Hexagon 690 DSP. We sat down with Gary Brotman, Head of AI and Machine Learning Strategy and Product Planning at Qualcomm, and Ziad Asghar, Vice President of Snapdragon Roadmap Planning and AI, XR, Competitive Strategy at Qualcomm, to learn more about the improvements Qualcomm made in AI workloads.
Mario Serrafero: “So, the new DSP. Last year, I asked you about the attack strategy with respect to how Qualcomm pushed, promoted, marketed, and communicated the DSP and HVX, in particular. At the time, as an AI block, it was still relatively new to most readers and consumers. So we’re wondering how you’ve seen this evolve since then with the further promotion of the 845.”
Gary Brotman: “First and foremost, when we started doing this back with the 820, it was still very CPU and GPU centric, and leveraging the DSP and the vector processing capabilities for that really came about as a result of where Google is trying to head with TensorFlow and 8-bit math. So that’s where we really stretched our legs in DSP, or let’s say the vector processors. Given the maturity of the vector processor that we have in Hexagon and the way we were able to advance that roadmap so quickly in the next two generations, and the use cases that we saw, which at the time, basic classification networks were pretty straightforward with not a lot of heft. They can run fine with 8-bit math. A dedicated accelerator, even last year, was a risk for basically allocating area to something that may not get used. The confluence for use cases, and it’s anything from your standard single camera, super resolution, or segmentation in real time. These things happening in some cases, concurrently, the demand for having at least some level of dedicated acceleration you can wall off and still read cycles on the vector processor or even the GPU. It was the right time.
It’s certainly something we had to plan for much earlier than when we talked last time, but I think everybody in this business is placing a bet that they know exactly, or close to exactly, what those workloads are going to be. What type of precision should be necessary, and if you did or did not budget enough compute to satisfy that confluence of use cases that are coming. We’re pretty deliberate in that—Qualcomm’s always been use case centric—and we didn’t want to run the risk of having dedicated acceleration that wouldn’t be used because it could be out of date in the last cycle. We see enough in terms of general convolution alone that a dedicated accelerator can do a fantastic job of. Again, freeing up the cycles elsewhere. In terms of the strategy that we have with this new accelerator: It is dedicated, it’s a new architecture. It’s not a Hexagon derivative. But if you think about a net today, there are certain nonlinearity functions that don’t run well on some of the dedicated acceleration -“
Mario Serrafero: “Yeah, sigmoid, ReLU -“
Gary Brotman: “Exactly, Softmax. And you have to punt them elsewhere, or to the CPU. But in our case, the way that we’ve kind of engineered this under the hood, the DSP is actually the control. It determines where the net runs and where the layers run and can decide if there’s certain things that should run on the DSP as a fallback versus run on the tensor processor. So that pairing actually made a lot of sense to us. But that doesn’t detract from our beliefs and our strategy that every primary core in our SoC has a role, so we optimize across the board, yet there’s still a lot of variability and that’s going to continue.”
Mario Serrafero: “Another topic that we want to talk about is use cases. Like you said, Qualcomm is very use case centric, we’ve seen AI come to mobile in three main areas: speech recognition, sequence prediction like with strings and typing, and obviously computer vision like AI filters, [and object recognition]. Computer vision exploded, now you see it everywhere. I’ve seen with speech recognition, everyone’s got their own AI assistant, everyone’s got their own assistant. Now, all that can be done at the edge with small latency and perfect security. But what’s next for use cases of machine learning, and are all those use cases going to be developed by the big companies in the world – all the Snapchats in the world, the Facebooks out there? How do you see that rolling?”
Gary Brotman: “I don’t think I can point out a killer use case. But the capabilities allow for more computational complexity and in the case of vision, the input resolution can be higher. You’re not working on low resolution images to do bokeh. There was a discussion earlier in the other interview we had around 4K streaming as an example. I’m not going to predict that that’s possible, but the developers that we work with, whether it’s big companies like Google or our software development partners who are actually building the algorithms that are driving a lot of these mobile features, they just want to push more. They want to go farther. If there’s anything that I would see in terms of next steps, it would probably be less about what’s happening above the line or at the app level, and more about what’s happening in the system like improving the way the product works, power management, and even in the camera pipeline, not just on top of it. You mentioned audio, and how many keywords you’re going to support or if you could do noise cancellation on-device. The keyword thing is interesting because it’s not easy to build up the library—you’re memory constrained. So there’s still going to be a balance between what’s local and what’s going to happen in the cloud.”
Ziad Asghar: “I can add a little. So at least the two domains where it’s kind of growing a lot are audio and imaging, today. We can see it having a lot of use cases. Jack talked about it from a camera perspective, we’ve had the AI engine where you can leverage a lot of that for imaging use cases. Some of the ones that were shown today. And then if you look at audio, we didn’t talk as much about it, but we actually added some audio capabilities to the audio block as well. We’re able to do better voice activation in more noisy environments. We’re able to do better noise cancellation [in imaging]. All of those abilities are basically already happening. There are the partners that Gary showed today for the ISP, there are a lot more of those coming. So I think those are the two dimensions that we are more focused on today.”
Gary Brotman: “And then the next step—I’m not going to forecast when this happens—is there is enough compute now where on-device learning and experimentation around actual learning on the device will likely happen in this next cycle.”
Mario Serrafero: “This is probably a topic that’s more fun to discuss, and it’s the fact that Qualcomm is sticking with the Hexagon DSP moniker and HVX while other companies are opting for “neural” so and so. How does Qualcomm see this discrepancy and these different strategies and approaches with mainly the marketing, but we can go into a bit later about the heterogeneous compute versus specific block bits as well.”
Gary Brotman: “Because Hexagon already has equity built up in DSP, that one would immediately gravitate towards thinking they we’re just extending our DSP strategy. Actually on brand, if you look at all three processors, your scalar, your vector, and now your dedicated tensor accelerator, they’re not all DSP. Hexagon is really a higher level brand than just DSP. There is a handful of DSPs. I think the marketing questions are probably a little bit more difficult to answer because each region is different. China’s very NPU-centric because that is a moniker that had been introduced last year, and that seems to be one that has taken root. I wouldn’t say that that’s worked elsewhere around the globe. Google has a tensor processor, and tensor seems to resonate.”

The Qualcomm Snapdragon 855’s improvements in AI workload performance. Source: Qualcomm.

Mario Serrafero: “A lot of people have their own different names.”
Gary Brotman: “Ultimately, it comes down to what the OEM wants to do. If that matters to their customers, then it’s incumbent upon them to figure out how they can leverage that processing capability and differentiate upon it in terms of capabilities. Our engine, and I think a great deal of the processing capability that we have, would still be very vector and tensor-centric in terms of the overall mix. The dedicated processing itself, the way it does matrix multiplication, it’s the same sort of dedicated processor that an NPU would be [using]. The marketing question is an interesting one, and I forget, what was Keith’s answer?”
Ziad Asghar: “His answer was, ‘you can call it whatever you want to, to be able to sell more product.'”
Gary Brotman: “That was pretty much it; that was right, it was a very blunt answer.”
Ziad Asghar: “I think Gary covered it really well. Some of the people using that moniker as a term in a way that almost states or implies that it’s only limiting it to that block. But what we see is that this whole heterogeneous approach of being able to use the CPU, or a GPU, or a Hexagon tensor vector, gives you different trade-offs in a whole spectrum of precision on power and performance, and that’s what you need today. Because we don’t know what application requires what degree of precision, what requires sustained performance, or what doesn’t require it. So we believe it’s that a full, overall solution because that’s how you get the best experience”
Gary Brotman: “And that’s never changed in any of our conversations, even with a dedicated accelerator. It’s an addition, it’s not a replacement.”
Mario Serrafero: “Yeah, I think it was Keith last year who said, ‘where there’s compute, there’ll be AI.’ And now there’s more compute.”
Gary Brotman: “More compute in every block, that’s exactly right.”
Mario Serrafero: “Now that we are on the subject, we’ve heard many comparisons with a “mysterious” 7nm competitor on Android. Yeah, we still have no clue who that is.” (spoken in jest)
Gary Brotman: “No idea.” (spoken in jest)
Mario Serrafero: “But, could you clue us in on these comparisons? How were they measured? What caveats are worth considering? Any other comments that maybe you guys didn’t have time to expand upon in the slides or in the Q&A? I know it’s kind of hard to measure [and communicate] because of the variety of models, so I think it’s an interesting subject to expand upon to let people know why it’s not that easy to make those comparisons.”
Gary Brotman: “It’s actually quite simple. I’ll give you a very simple answer on one specific metric; we’re going to be doing more benchmarking in January. We’ll talk more about the different nets that are used to measure the numbers that we’re basing it on, and that would be standard Inception v3. That’s where we’re deriving that performance and our understanding of where the competition ranks. But in terms of the one that has announced and is out with products in the market, that’s where the 2x and the 3x comes from—well the 3x was against what we had in 845, while the 2x is their measure of performance and state of performance relative to ours.”
Ziad Asghar: “You have devices available, you can actually acquire them and do some of that testing yourself. But I think the only thing I would guard against, it is kind of a Wild West of benchmarking AI. Some people are using some very generalized terms, or mixes of networks which might benefit them in a particular way or not. “Will that align well with a modal workload?” is not something that people are keeping into consideration. Some of the benchmarks that have been floating around do a lot more of that, and we’re very close so we know there are people who are making those benchmarks sway one way or another depending on what favors them. That’s why it’s a lot more about actual use cases. It’s also a lot more about the best-in-class performance for that use case, and then it is about getting it done quickest. I think those are all the factors that we look at. But I think it will become better, it will converge. Right now, there’s a variety of different options out there. I think you will have certain benchmarks stay that make more sense. Today, maybe you could argue Inception v3 is relatively better at this point in time.”
Gary Brotman: “In terms of networks, there’s a handful. There’s ResNet, VGG, segmentation nets, super resolution nets—raw performance you could measure these with. The point to take away in terms of benchmarks like companies or entities that are doing AI benchmarking, and they have mixtures of precisions, networks, and formulas that are variable, they’re so variable the results change week-to-week. That’s where it’s truly the Wild West, and we’re keeping an arm’s length. We’re not placing our bets anywhere, because there is so much variability when it comes to the actual performance by some of these networks that are used in use cases, we feel confident that we’re still definitely ranking up there in terms of performance relative to the competition. I should say not ranking but the doubling that we talked about, raw performance.”
Mario Serrafero: “One of the subjects that we are interested in as a site primarily for developers is the democratization of machine learning. Obviously, we have open source libraries which are great, everyone’s offering these amazing SDKs as well, and there’s plenty of education. And now Android NN is available and Google just released ML Kit which simplifies the process. You just call an API, feed it your input, they use a trained model, you don’t have to worry about it, you don’t have to think about it, you don’t have to know any stats or any vector calculus. How do you see that the landscape has evolved in this regard in making it more accessible, simplifying the API, simplifying the documentation, the SDKs, and promoting the inclusion of third-party developers, not just big companies?”
Gary Brotman: “It’s funny when we actually focus on big companies, it’s helping the smaller developers as well. We started off with more of a proprietary stack when it came to programming for Snapdragon, specifically for running AI. But over time, and in the last couple of generations, we’ve added more tools. We are trying to strike a balance between high-level abstraction and ease of use, and lower-level access, which requires somebody to be much more savvy especially when it comes to dealing with some of our proprietary cores like the vector processor or the NPU. We see it evolving from a democratization standpoint. We have the basic building blocks like Hexagon and Qualcomm math libraries, but maybe a slightly higher level API that abstracts at least some of that heavy lifting, but gives enough of a flexibility to the developer to be able to use their own custom operators, or be able to tweak a little bit in terms of performance at the lower level. So the portfolio will continue to involve more tools, and certainly things like NN API where Onyx is an example for being able to basically say “here’s what you’re programming, what you’re expressing your network in.” As long as the hardware supports it, you’re good.
As I mentioned in our presentation, we are responsible for a multi-OS landscape. There’s Windows, there’s Linux, there’s Android, so it’s not just about Android. When we look at this, if we’re going to construct some sort of an API that is going to be SoC, cross-SoC, or cross-platform from an OS standpoint, we have to look and see how to find commonality in what we build under the hood. The stack with libraries and operator support and having that be able to plug into NN API or Windows ML, as an example. But certainly, we’ve gone from the pendulum being over here where nobody really knows what to do, like literally, not knowing. “I don’t know what framework to use. Do I use TensorFlow, or should I use Caffe or Torch?” And not knowing what to do to optimize at the lower level. So everybody’s happy with an API call. Now, within just a matter of a couple of years, it’s easy to go deeper. So the tools are there, whether they’re common open source tools, or even in a portfolio like we offer or competitors offer, those tools are becoming more easily accessible and easier to use.”

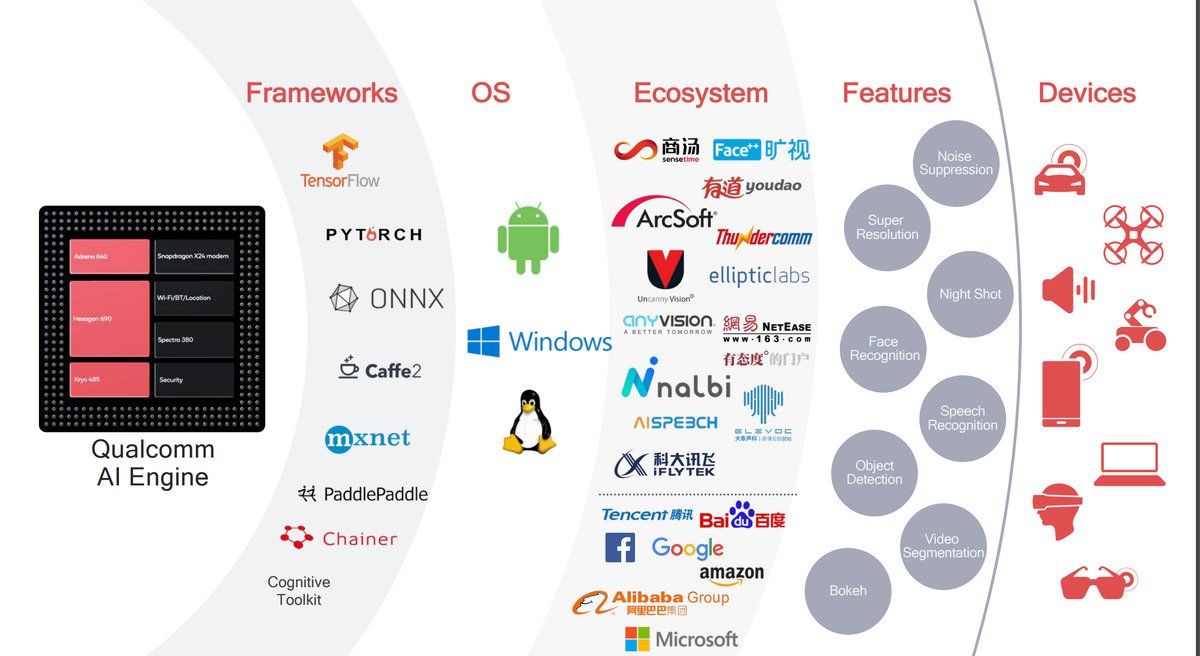
Qualcomm’s AI Engine and supported AI frameworks, operating systems, ecosystems, features, and devices. Source: Qualcomm.
Mario Serrafero: “Speaking of developer communities. Last time we had mentioned one of the most mature communities that we have is the gaming community, and Qualcomm’s pretty well embedded in that. Now, we see that more than ever with the partnerships with the game engines that are being promoted and marketed. So we were talking about that in the context of AI and how it’s emerging there.”
Mishaal Rahman: “You were talking about how you wanted to invest more over the next 12 months. This was back during the last time we were here.”
Mario Serrafero: “In specifically the gaming developer community, kind of expanding upon that and what we see today.”
Gary Brotman: “I don’t remember the specific comment about investing in the gaming community, but if you look at a category that we saw driving the need for dedicated acceleration, and gaming is a component of this, but it’s not the primary use case necessarily—VR as an example. In a rich, immersive VR experience, every core is basically leveraged. You’re doing graphics processing on the GPU, visual processing on the vector processor, and the need to take one or many nets and run them separately on a dedicated accelerator without the worry of concurrency impact. That’s one of the reasons that drove us down the path of having dedicated acceleration. I don’t have a lot of information with respect to how AI is being leveraged in games today. There’s a lot of work with agents—developing agents to combat against or teach you.”
Mario Serrafero: “Like the traditional AI in games.”
Gary Brotman: “Exactly, right. But being more neural network based.”
Mario Serrafero: “Yeah, not the Minimax.”
Gary Brotman: “Part of Ziad’s responsibility too is driving XR strategy.”
Ziad Asghar: “XR wise, if you look at it today, we have launched new devices that are all-in-one HMDs with full 6DOF enablement. Devices like the Oculus Quest that launched actually with the Snapdragon 835, so we are starting to get to a very good point in terms of actually harnessing the full ability of XR devices. In the past, some of the devices were not really giving that pristine experience because some people have not gotten the best experience out of it. I think XR is now doing great. What we are also looking at in the future as it combines with 5G, is it allows you to now be able to take your device that’s actually much more mobile which means you can envision that you’re actually walking on a street. And then having a link like 5G means that like the demo that Gary showed of Google Lens. Now imagine that if you were wearing some sort of Google Glasses or something like that and you’re able to actually bring in information all towards what you’re looking at through your eyes, now you have a use case that really could be very compelling. I think that’s where the long-term investment that you’re talking about, that’s kind of the direction that it goes.
But right now, we feel we’re in a very good state in terms of XR and all the different companies that have launched with XR. Oculus Go is also based on Snapdragon 820, so I think we’re starting to get to a very good point where people are picking it up and doing a lot of things with it. And the next stage like I mentioned is we start to bring in 5G connectivity which we’ll do and then beyond that of course AR and some things that will even require much more in terms of performance, yet limited on power. And that’s going to be extremely challenging, and I think with what we talked about today, Qualcomm is probably the best in terms of doing any of these use cases in terms of power. If you look at graphics, if you benchmark any of the competitors you’ll see our performance-per-unit-power is best-in-class. And as a consequence of that, the thermals, the sustained performance is what matters in XR, and in that regard we’re really ahead—that’s the reason why people use us for XR.”

The Oculus Go is powered by the Qualcomm Snapdragon 821 mobile platform.

Mario Serrafero: “Since last year, we’ve seen the Hexagon 685 DSP finally hit the premium mid-range with the 710 and the proper mid-range with the 670 and 675. So now we’re getting the Hexagon Vector Extensions making their way downstream whereas other competitors are not quite doing that with their neural processing units. How do you see that extending the reach of these experiences, and I wanted to ask whether, in the past, you saw the performance discrepancies in AI make a difference at all? Because we still kind of are in the early adoption of AI.”
Ziad Asghar: “I look at the overall roadmap. If you’re looking for the pristine best-in-class performance, it’s going to be in the premium tier. What we’re doing is we’re selectively taking some of the Hexagon capabilities and bringing it lower. The first AI engine, or the first Hexagon, was started with the Snapdragon 820. So we’ve brought it down to the Snapdragon 660 and into 670, and 710 has it also. So, our plan is to see how it breaks into the prospective experiences.
As an AI engine, we have basic old components: CPU, GPUs, Hexagon tensor, Hexagon vector, and scalar. What we do is we selectively bring parts of that further down into the roadmap as we see that those abilities are coming down and going into lower tier headsets. You will see actually, as we go further in the year. you’ll see we’ll do more of that. We launched Snapdragon 675 at the 4G/5G Summit. We talked about that coming down with the 675, and what you will see is, as these use cases are becoming more prevalent, as we showed with ArcSoft and all those other guys today, we will actually bring these capabilities lower. In the lower tier you will be able to run that use case, but to be able to get that right power profile like I talked about earlier, if you want to have that sustained performance, you want that particular block to be coming lower. So again, best-in-class performance will be up top, but as you go lower there will be a great degradation or gradation of…”
Mario Serrafero: “Gradient descent, you could say.” (spoken in jest)
Ziad Asghar: “Yeah, exactly. That’s kind of how we do with other technologies also on the roadmap and AI is not going to be very different in that sense. It is probably one difference, perhaps where you’re coming from, as it is probably coming down faster through other technologies that we have brought down in the roadmap, so that observation I’d agree with.”
If you’re interested in learning more about AI in Qualcomm’s mobile platforms, we recommend reading our interview from last year with Gary Brotman. You can start with part 1 of our interview or go to part 2.
All graphics shown in this interview are sourced from Gary Brotman’s presentation during the Snapdragon Tech Summit. You can view the slides here.



0 comments:
Post a Comment